Introduction
At the intersection of generative AI (GenAI), architecture and urban studies, the representational power of synthetic place—computationally aggregated approximations of real sites—offers unprecedented opportunities for collective imagination. However, this rapidly evolving technology raises critical questions about representation, bias, and the ethics of place-based AI systems. Given the speed of innovation in artificial intelligence (AI) and GenAI, a critical question emerges: Whose collective imagination are we amplifying as we steward this technology?
This research has investigated the systematic erasure of local diversity through generative and predictive machine learning models, driven by centralized technologies and datasets predominantly from the Global North. We argue that these models construct synthetic realities that often fail to capture the nuances and specificities of place, particularly in underrepresented regions. This problem is exacerbated by the tendency of these models to default to stereotypical or generic representations when dealing with less-documented locales.
As computational designers, we find ourselves at a critical juncture where the responsible development and application of AI technologies have become imperative. The widening gap between real-world localities and their digital simulations, particularly in the context of GenAI and Digital Twins (DTs), threatens to reshape our understanding of urban and rural spaces. This shift has the potential to influence our perception of place, thus informing governance and planning decisions in obscure ways which may not accurately reflect the complexities of localities and real lived experiences.
The inception of our research question dates back to a project proposal we developed for the Magic Grant 2024 by Brown Institute at Columbia University. Since then we've been expanding, exploring and building – new tools, computational experiments and a network of researchers which investigate the role of generative AI in changing our perceptions of localities.
Vision RAG Tool
We continued our initial research proposal at the Hack/Hackers + Brown Institute hackathon at Columbia University in April 2024, where over 100 journalists, technologists, and designers came together to reimagine the intersection of journalism and AI where we joined forces with Zachary B. from Codingscape to tackle one critical question: How can AI-generated imagery serve more nuanced representations of place?

Hack/Hackers + Brown Institute hackathon
Columbia University, April 2024 - Presentation and collaborative work during the hackathon
Too often, early text-to-image generation tools in 2024 returned generic, Westernized versions of real places. Playground XL when prompted to generate [PROMPT GOES HERE], returned a fantastical representation of the Bab Mahrouk gate in Morocco, a UNESCO heritage site that is a relevant historic site in the northeastern Moroccan city Fes, yet less well-captured by global tourism, that more closely resembles the Arc de Triomphe, a popular site and icon in world history. This is more than a design flaw—it's a reflection of whose images, data, and geographies are being prioritized in global datasets.

AI-Generated vs. Real Architecture
Left: AI-generated Bab Mahrouk gate using Playground XL, Right: Actual UNESCO heritage site in Fes, Morocco
We hypothesized that by expanding the scope of 'ground-truth sources' we could fine-tune the results without amending the base-LLM's ourselves. Our resulting Vision Retrieval-Augmented Generation (RAG) tool combined a number of API's and Gen-AI models to then re-format user's prompt like:
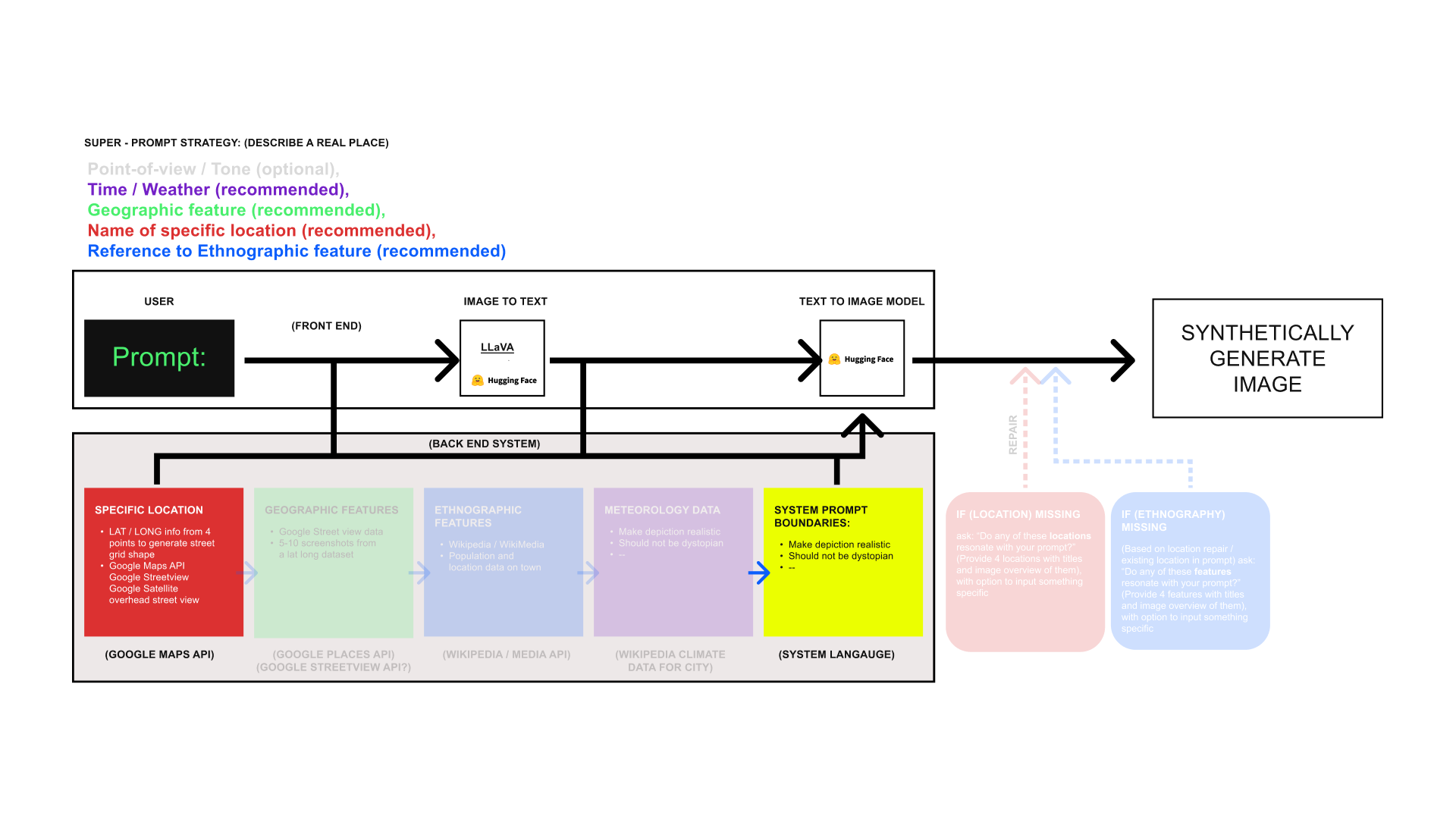
RAG Tool Pipeline
LLaVA, SDXL-Turbo, Add all components of Vision Rag Tool Pipeline
With this model, when we prompted a sample set of different localities such as "Paris". Instead of vague romanticized representations, the output included more accurate building styles, lighting, local textures, and everyday pedestrians. The output felt more grounded—because it was informed by place-based spatial data.


RAG Tool outputs for two cities
Vision-Rag Tool for Tokyo and Paris
AI & Cities 2024 - Digital Double
In Fall of 2024, we further developed our research at the "AI & Cities 2024 - Digital Double" symposium in Rome at the Max Planck Institute with ETH Zurich where we first publicly presented our "Prompts & Provenance: Decoding Digital Geographies - AI's Interpretation and Our Exploration of Global Localities," at the symposium hosted @Bibliotheca Hertziana.

AI & Cities 2024 Symposium Presentation
Rome, IT Max Planck Institute at AI & Cities 2024 - Digital Double Symposium
Organized by Darío Negueruela del Castillo, Julio Paulos, and Nicolo' Guariento, the event was a dynamic two-day exploration into the role of emerging technologies, future of cities, digital twins, and artificial intelligence. It was an inspiring exchange of ideas, with a diverse array of projects and stimulating discussions on the intersection of technology, theory and urban environments.



Research Presentation Slides
Rome, IT Max Planck Institute at AI & Cities 2024 - Digital Double
Impact on Media and Representation
In our media-based world - journalism and public storytelling, visual representation is everything. Misrepresentation through AI imagery doesn't just flatten culture; it risks erasing it. If, as studies suggest, 90% of online images may be synthetically generated by 2026, we need systems that reflect the world, not just the parts of it that fit within Western paradigms.
Inaccurate images can perpetuate stereotypes, ignore local nuance, and reinforce a Western gaze. For newsrooms or anyone using AI in representational contexts, this creates an ethical issue.
This project is part of our broader research into spatial representation, machine perception, and public trust in generative media. As designers and researchers, we're less interested in replacing human perception with AI, and more interested in helping systems see the world more clearly—on our terms, not just the dataset's.
Conclusion
As we continued testing generative AI models, we observed a marked improvement in visual fidelity following the release of OpenAI's multimodal GPT-4.0 in April 2025. When prompted with the same inputs, outputs became more detailed and place-specific. Yet this raises a critical question: Are these improvements the result of deeper, more accurate geographical knowledge within the model's dataset—or simply better prompt engineering and retroactive fine-tuning designed to appear more ethical? The distinction matters, especially when visual outputs risk being mistaken for representations rooted in cultural understanding, rather than computational approximation.
Future Directions
This May we will show our work at the Venice Biennale d'architettura 2025. In parallel to the installation we've developed Prompts & Provenance as an online space, which informs about our research and visual investigations into Generative AI and the underlying mechanics of tokenization and encoding.
We are deeply grateful to the Brown Institute and the Hacks/Hackers community for fostering a space where critical inquiry meets technical experimentation—and to mentors like Laura Kurgan and Mark Hansen, whose guidance continues to shape our approach at the intersection of AI, digital humanities, geography, and media. Our thanks also go to Darío, Julio, and Nicolò for curating a truly generative symposium in Rome that pushed these conversations further.
Through Prompts & Provenance, we hope to ignite broader dialogue about the ethical responsibilities embedded in AI-generated media and its impact on spatial and cultural perception. This work is not about replacing human interpretation, but about designing systems that are more attuned to local knowledge, lived experience, and visual nuance.
Looking Ahead
As synthetic images increasingly define how we see the world, we ask: What does our future perception of the world look like as we increasingly see through AI? And how can we ensure we don't lose our place in the process of synthetic representation?
To learn more about the hackathon, check out our Vision-RAG blog post with Hugging Face and Codingscape.